In this we discuss some of the basic terms and Machine learning fundamentals that are relevant for model evaluation, namely bias, variance, under fitting, over fitting.

The over all goal in Machine learning is to obtain a model that generalizes well to new, unseen data. Some of the evaluation metrics we can use to measure the performance on the test set are the prediction accuracy and misclassification error in the context of classification models, we say that model has a "High generalization accuracy" or " Low generalization error".
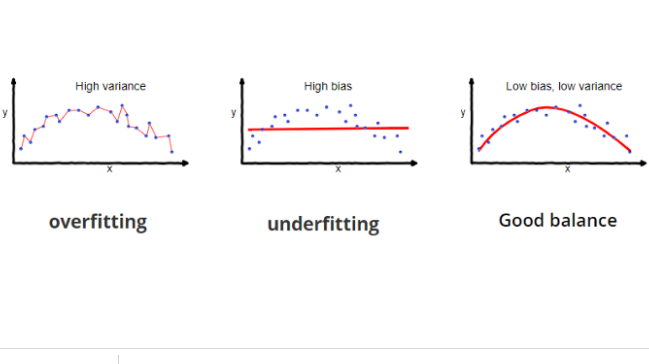
In general, we might say that high variance is proportional to over fitting and high bias is proportional to under fitting. Let's see these terms more precisely.
Bias:
The bias is the difference between prediction values by model and actual values. Being high biasing gives a large error in training as well as testing data. It's recommended that an algorithm should always be low biased to avoid the problem of under fitting.
Variance:
The variability of model prediction for a given data point which tells us spread of our data is called the variance of the model. The model with high variance has very complex fit to the training data and this is not able to fit accurately on the data which it hasn't seen before. As a result, such models perform very well on training data but has high error rates on test data. When a model is high on variance, it is then said to as over fitting of data.


Comments
Post a Comment